Artificial Intelligence
Attached Image data set from combined OCT-SLO is used to train AI models and identify features to maximize quality of data set to adjust MZI reference arm, PMT Voltage of Liquid Lens and location of object. Why adjustment is needed is explained below:
- Categories:
 77 Views
77 Views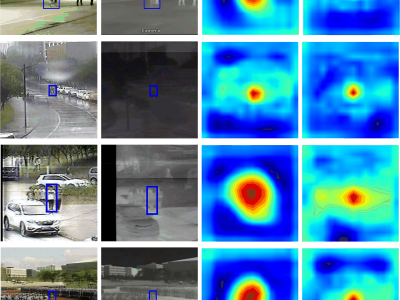
We are pleased to submit our manuscript entitled "Hetero-modal Template Guide Search Region for RGBT Tracking" for consideration for publication in IEEE Transactions on Consumer Electronics. This work presents a novel framework for robust RGB-Thermal (RGBT) object tracking, addressing critical challenges in consumer electronics applications such as smart security systems, autonomous navigation, and augmented reality devices.
- Categories:
110 Views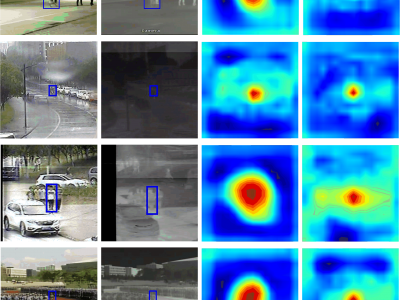
We are pleased to submit our manuscript entitled "Hetero-modal Template Guide Search Region for RGBT Tracking" for consideration for publication in IEEE Transactions on Consumer Electronics. This work presents a novel framework for robust RGB-Thermal (RGBT) object tracking, addressing critical challenges in consumer electronics applications such as smart security systems, autonomous navigation, and augmented reality devices.
- Categories:
74 Views
This dataset consists of meteorological and environmental data collected in Riyadh, Saudi Arabia, over multiple years. The variables include solar radiation, temperature (both maximum and minimum in Celsius and Fahrenheit), precipitation, vapor pressure, and snow water equivalent, among others. The data spans from 2010 to the present, providing insights into solar radiation patterns, daily temperature fluctuations, and weather-related factors that can impact solar power generation. Specifically, the dataset contains the following columns:
- Categories:
22 Views
This study explores the relationship between social media sentiment and stock market movements using a dataset of tweets related to various publicly traded companies. The dataset comprises time-stamped tweets containing company-specific information, stock ticker symbols, and company names. By leveraging natural language processing (NLP) techniques, we analyze the sentiment of tweets to determine their impact on stock price fluctuations. This research aims to develop predictive models that incorporate tweet sentiment and frequency as features to forecast stock price movements.
- Categories:
24 Views
Ensemble clustering, which integrates multiple base clusterings to enhance robustness and accuracy, is commonly evaluated on over 10 benchmark datasets. These include 4 synthetic datasets (e.g., 3MC,atom,Tetra and Flame) designed to test algorithms on nonlinear separability and density variations.
- Categories:
6 Views
SNMDat2.0 is a comprehensive multimodal dataset, expanded from the unimodal TwiBot-20, designed for Twitter social bot detection. Specifically, we add 274587 profile images and profile background images, 86498 tweet images and 49549 tweet videos based on the original 229580 twitter users, 227979 follow relationships and 33488192 tweet text.
- Categories:
9 Views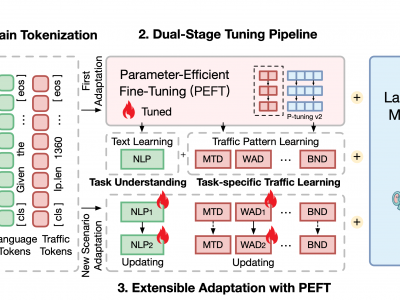
We released TrafficLLM's training datasets, which contain over 0.4M traffic data and 9K human instructions for LLM adaptation across different traffic analysis tasks.
- Categories:
113 Views
The painting style data sets were constructed by searching, selecting and collecting the public painting works on the internet, treating the painting style and artists' names as keywords. The data set collected 750 painting works in all, including five kinds of styles. They were receptively Cubism, Op Art, Color Field Painting, Post Impressionism and Rococo.
- Categories:
8 Views
Amid global climate change, rising atmospheric methane (CH4) concentrations significantly influence the climate system, contributing to temperature increases and atmospheric chemistry changes. Accurate monitoring of these concentrations is essential to support global methane emission reduction goals, such as those outlined in the Global Methane Pledge targeting a 30% reduction by 2030. Satellite remote sensing, offering high precision and extensive spatial coverage, has become a critical tool for measuring large-scale atmospheric methane concentrations.
- Categories:
6 Views